Spark RDDs 基本操作、RDDs 特性、KeyValue 对 RDDs、RDD 依赖
RDD 是 Spark 中极为重要的数据抽象,这里总结 RDD 的概念,基本操作 Transformation (转换) 与 Action,RDDs 的特性,KeyValue 对 RDDs 的 Transformation(转换)。
1.RDDs 是什么
Resilient distributed datasets(弹性分布式数据集) 。RDDs 并行的分布在整个集群中,是 Spark 分发数据和计算的基础抽象类,一个 RDD 是一个不可改变的分布式集合对象,Spark 中,所有的计算都是通过 RDDs 的创建,转换操作完成的,一个 RDD 内部由许多 partitions (分片)组成。
分片:每个分片包括一部分数据,partitions 可在集群不同节点上计算;分片是 Spark 并行处理的单元,Spark 顺序的,并行的处理分片。
2.RDDs 的创建
-
把一个存在的集合传给
SparkContext的parallelize()方法,测试用val rdd = sc.parallelize(Array(1,2,3,4), 4)第一个参数:待并行化处理的集合;第二个参数:分片个数
-
加载外部数据集
val rddText = sc.textFile("hellospark.txt")
3.RDD 基本操作之 Transformation(转换)
从之前的 RDD 构建一个新的 RDD,像 map() 和 filter()。
逐元素 Transformation
map(): 接收函数,把函数应用到 RDD 的每一个元素,返回新 RDD。
val lines = sc.parallelize(Array("hello", "spark", "hello", "world", "!"))
val lines2 = lines.map(word => (word, 1))
lines2.foreach(println)
//结果:
(hello,1)
(spark,1)
(hello,1)
(world,1)
(!,1)
filter(): 接收函数,返回只包含满足 filter() 函数的元素的新 RDD。
val lines = sc.parallelize(Array("hello", "spark", "hello", "world", "!"))
val lines3 = lines.filter(word => word.contains("hello"))
lines3.foreach(println)
//结果:
hello
hello
flatMap(): 对每个输入元素,输出多个输出元素。flat 压扁的意思,将 RDD 中元素压扁后返回一个新的 RDD。
val inputs = sc.textFile("/home/lucy/hellospark.txt")
val lines = inputs.flatMap(line => line.split(" "))
lines.foreach(println)
//结果
hello
spark
hello
world
hello
!
//文件内容/home/lucy/hellospark.txt
hello spark
hello world
hello !
集合运算
RDDs 支持数学集合的计算,例如并集,交集计算。
val rdd1 = sc.parallelize(Array("red", "red", "blue", "black", "white"))
val rdd2 = sc.parallelize(Array("red", "grey", "yellow"))
//去重:
val rdd_distinct = rdd1.distinct()
//去重结果:
white
blue
red
black
//并集:
val rdd_union = rdd1.union(rdd2)
//并集结果:
red
blue
black
white
red
grey
yellow
//交集:
val rdd_inter = rdd1.intersection(rdd2)
//交集结果:
red
//包含:
val rdd_sub = rdd1.subtract(rdd2)
//包含结果:
blue
white
black
4.RDD 基本操作之 Action
在 RDD 上计算出来一个结果。把结果返回给 driver program 或保存在文件系统,count(), save。
| 函数名 | 功能 | 例子 | 结果 |
|---|---|---|---|
| collect() | 返回RDD的所有元素 | rdd.collect() | {1,2,3,3} |
| count() | 计数 | rdd.count() | 4 |
| countByValue() | 返回一个map表示唯一元素出现的个数 | rdd.countByValue() | {(1,1),(2,1),(3,2)} |
| take(num) | 返回几个元素 | rdd.take(2) | {1,2} |
| top(num) | 返回前几个元素 | rdd.top(2) | {3,3} |
| takeOrdered(num)(ordering) | 返回基于提供的排序算法的前几个元素 | rdd.takeOrdered(2)(myOrdering) | {3,3} |
| takeSample(withReplacement,num,[seed]) | 取样例 | rdd.takeSample(false,1) | 不确定 |
| reduce(func) | 合并RDD中元素 | rdd.reduce((x,y)=>x+y) | 9 |
| fold(zero)(func) | 与reduce()相似提供zero value | rdd.fold(0)((x,y)=>x+y) | 9 |
| foreach(func) | 对RDD的每个元素作用函数,什么也不返回 | rdd.foreach(func) | 无 |
5.RDDs 的特性
-
血统关系图:
Spark 维护着 RDDs 之间的依赖关系和创建关系,叫做血统关系图,Spark 使用血统关系图来计算每个 RDD 的需求和恢复丢失的数据
-
延迟计算
Spark 对 RDDs 的计算是,他们第一次使用
action操作的时候。Spark 内部记录 metadata 表明 transformations 操作已经被响应了。加载数据也是延迟计算,数据只有在必要的时候,才会被加载进去。 -
RDD 持久化
Spark 最重要的一个功能是它可以通过各种操作持久化(或者缓存)一个集合到内存中。当持久化一个 RDD 的时候,每一个节点都将参与计算的所有分区数据存储到内存中,并且这些数据可以被这个集合(以及这个集合衍生的其他集合)的动作(action)重复利用。这个能力使后续的动作速度更快(通常快10倍以上)。对迭代算法和快速的交互使用来说,缓存是一个关键的工具。
可以通过
persist()或者cache()方法持久化一个 rdd。首先,在 action 中计算得到 rdd;然后,将其保存在每个节点的内存中。Spark 的缓存是一个容错的技术 - 如果 RDD 的任何一个分区丢失,它可以通过原有的转换(transformations)操作自动的重复计算并且创建出这个分区。此外,可以利用不同的存储级别存储每一个被持久化的 RDD。例如,它允许我们持久化集合到磁盘上、将集合作为序列化的 Java 对象持久化到内存中、在节点间复制集合或者存储集合到 Tachyon 中。我们可以通过传递一个
StorageLevel对象给persist()方法设置这些存储级别。cache()方法使用了默认的存储级别 —StorageLevel.MEMORY_ONLY。完整的存储级别如下:Storage Level Meaning DISK_ONLY,&_2 仅仅将 RDD 分区存储到磁盘中 MEMORY_ONLY,&_2 将 RDD 作为非序列化的 Java 对象存储在 jvm 中。如果内存装不下原始文件那么大的数据,一些分区将不会被缓存,从而在每次需要这些分区时都需重新计算它们。这是系统默认的存储级别。 MEMORY_ONLY_SER,&_2 将 RDD 作为序列化的 Java 对象存储(每个分区一个 byte 数组)。这种方式比非序列化方式更节省空间,特别是用到快速的序列化工具时,但是会更耗费 cpu 资源—密集的读操作。 MEMORY_AND_DISK,&_2 将 RDD 作为非序列化的 Java 对象存储在 jvm 中。如果内存装不下原始文件那么大的数据,将这些不适合存在内存中的分区存储在磁盘中,每次需要时读出它们。 MEMORY_AND_DISK_SER,&_2 和 MEMORY_ONLY_SER 类似,但不是在每次需要时重复计算这些不适合存储到内存中的分区,而是将这些分区存储到磁盘中。 OFF_HEAP (experimental) 以序列化的格式存储 RDD 到 Tachyon 中。相对于 MEMORY_ONLY_SER,OFF_HEAP 减少了垃圾回收的花费,允许更小的执行者共享内存池。这使其在拥有大量内存的环境下或者多并发应用程序的环境中具有更强的吸引力。
NOTE:在 python 中,存储的对象都是通过 Pickle 库序列化了的,所以是否选择序列化等级并不重要。
Spark 也会自动持久化一些 shuffle 操作(如 reduceByKey)中的中间数据,即使用户没有调用 persist 方法。这样的好处是避免了在 shuffle 出错情况下,需要重复计算整个输入。
如何选择存储级别?
- 如果你的 RDD 适合默认的存储级别(MEMORY_ONLY),就选择默认的存储级别。因为这是 cpu 利用率最高的选项,会使 RDD 上的操作尽可能的快。
- 如果不适合用默认的级别,选择 MEMORY_ONLY_SER。选择一个更快的序列化库提高对象的空间使用率,但是仍能够相当快的访问。
- 除非函数计算 RDD 的花费较大或者它们需要过滤大量的数据,不要将 RDD 存储到磁盘上,否则,重复计算一个分区就会和重磁盘上读取数据一样慢。
- 如果你希望更快的错误恢复,可以利用重复(replicated)存储级别。所有的存储级别都可以通过重复计算丢失的数据来支持完整的容错,但是重复的数据能够使你在 RDD 上继续运行任务,而不需要重复计算丢失的数据。
Spark 自动的监控每个节点缓存的使用情况,利用最近最少使用原则删除老旧的数据。如果你想手动的删除 RDD,可以使用 RDD.unpersist() 方法。
6.KeyValue 对 RDDs
创建 KeyValue 对 RDDs:
val rdd3 = sc.parallelize(Array((1,2),(3,4),(3,6)))
KeyValue 对 RDDs 的 Transformation(转换):
(1)reduceByKey(func)
把相同 key 的结合
val rdd4 = rdd3.reduceByKey((x, y) => x + y)
//结果
(1,2)
(3,10)
(2)groupByKey
把相同的 key 的 values 分组
val rdd5 = rdd3.groupByKey()
//结果
(1,CompactBuffer(2))
(3,CompactBuffer(4, 6))
(3)mapValues()
函数作用于 pairRDD 的每个元素,key 不变
val rdd6 = rdd3.mapValues(x => x + 1)
//结果
(1,3)
(3,5)
(3,7)
(4)keys/values
rdd3.keys.foreach(println)
//结果
1
3
3
rdd3.values.foreach(println)
//结果
2
4
6
(5)sortByKey
val rdd7 = rdd3.sortByKey()
//结果
(1,2)
(3,4)
(3,6)
(6)combineByKey()
(createCombiner,mergeValue,mergeCombiners,partitioner)
最常用的基于 key 的聚合函数,返回的类型可以与输入类型不一样。许多基于 key 的聚合函数都用到了它,像 groupByKey()
原理:遍历 partition 中的元素,元素的 key,要么之前见过的,要么不是。如果是新元素,使用我们提供的 createCombiner() 函数,如果是这个 partition 中已经存在的 key,就会使用 mergeValue() 函数,合计每个 partition 的结果的时候,使用 mergeCombiner() 函数
例子:求平均值
val score=sc.parallelize(Array(("Tom",80.0),("Tom",90.0),("Tom",85.0),("Ben",85.0),("Ben",92.0),("Ben",90.0)))
val score2=score.combineByKey(score=>(1,score),(c1:(Int,Double),newScore)=>(c1._1+1,c1._2+newScore),(c1:(Int,Double),c2:(Int,Double))=>(c1._1+c2._1,c1._2+c2._2))
//结果
(Ben,(3,267.0))
(Tom,(3,255.0))
val average=score2.map{case(name,(num,score))=>(name,score/num)}
//结果
(Ben,89.0)
(Tom,85.0)
7.RDD 依赖
Spark 中 RDD 的高效与 DAG 图有着莫大的关系,在 DAG 调度中需要对计算过程划分 stage,而划分依据就是 RDD 之间的依赖关系。针对不同的转换函数,RDD 之间的依赖关系分类窄依赖(narrow dependency)和宽依赖(wide dependency, 也称 shuffle dependency).
窄依赖是指父 RDD 的每个分区只被子 RDD 的一个分区所使用;宽依赖是指父 RDD 的每个分区都可能被多个子 RDD 分区所使用:
宽依赖和窄依赖如下图所示:
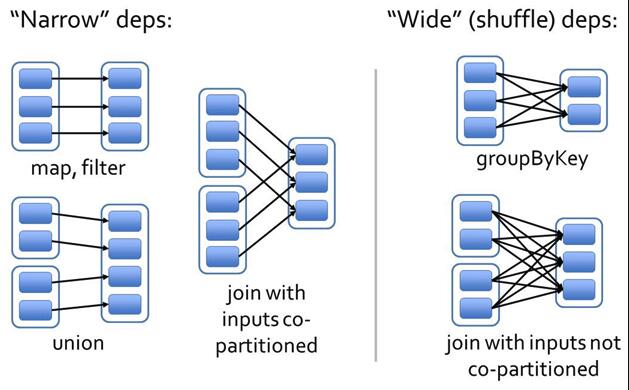
这种划分有两个用处。首先,窄依赖支持在一个结点上管道化执行。例如基于一对一的关系,可以在 filter 之后执行 map。其次,窄依赖支持更高效的故障还原。因为对于窄依赖,只有丢失的父 RDD 的分区需要重新计算。
对于宽依赖,一个结点的故障可能导致来自所有父 RDD 的分区丢失,因此就需要完全重新执行。因此对于宽依赖,Spark 会在持有各个父分区的结点上,将中间数据持久化来简化故障还原,就像 MapReduce 会持久化 map 的输出一样。