Hive 使用 load inpath 导入数据时出现 NULL 原因解析
最近给测试造一些 hive 的测试数据,先是使用 sqoop 从 mysql 导出数据到 hdfs,然后从 hdfs 导入数据到 hive。这是背景。
问题
在把 hdfs 上数据导入到 hive 表的时候,显示导入成功。
[root@hd-node1 ~]# hdfs dfs -ls /data/sqoop/test1_text
18/10/19 00:36:11 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 1 root supergroup 0 2018-09-23 15:52 /data/sqoop/test1_text/_SUCCESS
并且统计记录行数也是正确的。
hive> select count(*) from test_data_100w.test1_text;
Query ID = root_20181019005050_5d16fe1b-1964-4831-ba0b-371ea3b20d44
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1539108956909_0025, Tracking URL = http://hd-node1:8088/proxy/application_1539108956909_0025/
Kill Command = /opt/hadoop-2.6.0-cdh5.10.0/bin/hadoop job -kill job_1539108956909_0025
Hadoop job information for Stage-1: number of mappers: 2; number of reducers: 1
2018-10-19 00:50:26,009 Stage-1 map = 0%, reduce = 0%
2018-10-19 00:50:30,353 Stage-1 map = 50%, reduce = 0%, Cumulative CPU 2.09 sec
2018-10-19 00:50:33,440 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.89 sec
2018-10-19 00:50:36,537 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.83 sec
MapReduce Total cumulative CPU time: 5 seconds 830 msec
Ended Job = job_1539108956909_0025
MapReduce Jobs Launched:
Stage-Stage-1: Map: 2 Reduce: 1 Cumulative CPU: 5.83 sec HDFS Read: 23491228 HDFS Write: 7 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 830 msec
OK
100000
Time taken: 28.08 seconds, Fetched: 1 row(s)
hive>
悲剧的是查询数据都是 NULL,如图所示:
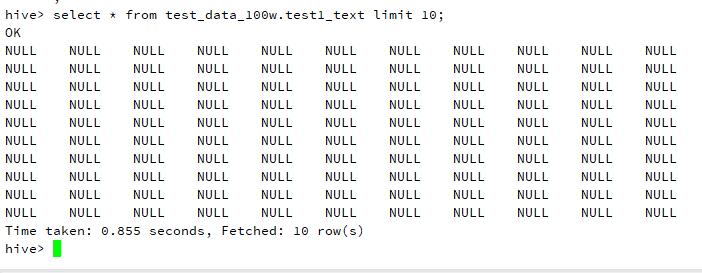
分析
如果出现数据为 NULL,一般都是因为在创建 hive 表的时候没有指定 列分隔符。
我在创建表的时候直接使用了简单的方式:
CREATE TABLE `test_data_100w.test1_text`(
`id` int,
`name` varchar(100)
}
看一下 sqoop 导出的文件中数据是怎么组织的。
[root@hd-node1 ~]# hdfs dfs -ls /data/sqoop/test10
18/10/19 01:15:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 5 items
-rw-r--r-- 1 root supergroup 0 2018-09-23 16:06 /data/sqoop/test10/_SUCCESS
-rw-r--r-- 1 root supergroup 4870859 2018-09-23 16:06 /data/sqoop/test10/part-m-00000
-rw-r--r-- 1 root supergroup 4881316 2018-09-23 16:06 /data/sqoop/test10/part-m-00001
-rw-r--r-- 1 root supergroup 4880618 2018-09-23 16:06 /data/sqoop/test10/part-m-00002
-rw-r--r-- 1 root supergroup 4880413 2018-09-23 16:06 /data/sqoop/test10/part-m-00003
[root@hd-node1 ~]# hdfs dfs -cat /data/sqoop/test10/part-m-00000
24997,康慨,40,2017-07-19 00:00:00.0,15200001111,65.51530571495157,四川省江油市洞庭湖广场138号-2-5,盖州画留航派贸易有限公司,le6l@sohu.com,371422199803278539
24998,顾卤,27,2017-07-19 00:00:00.0,15200002222,3302.0383016504006,湖南省岳阳市热河大厦90号-10-3,湖南衡阳另沙私针广告股份有限公司,sdsajb@yahoo.com.cn,450881195507138067
24999,钭誊,32,2017-07-19 00:00:00.0,15200003333,4349.148172354379,甘肃省兰州市汶水街48号-11-5,云南景洪真女谈严企业管理集团有限公司,qx5wb@126.com,653101195004073388
可以看到 sqoop 导出的 hdfs 分片数据,都是使用逗号 , 分割的,由于 hive 默认的分隔符是 /u0001(Ctrl+A),为了平滑迁移,需要在创建表格时指定数据的分割符号。
那么如果我们要导入这个数据,就需要在创建 hive 表的时候指定表的列分隔符为逗号。
CREATE TABLE `cetc_personal_infomation`(
`id` int,
`realname` string,
`identity_card` string,
`base_location` string,
`datetime` timestamp)
row format delimited fields terminated by ',';
然后重新从 hdfs 上 load 数据:
load data inpath '/data/sqoop/cetc_personal_infomation' into table cetc_personal_infomation;
查看 hive 表数据:
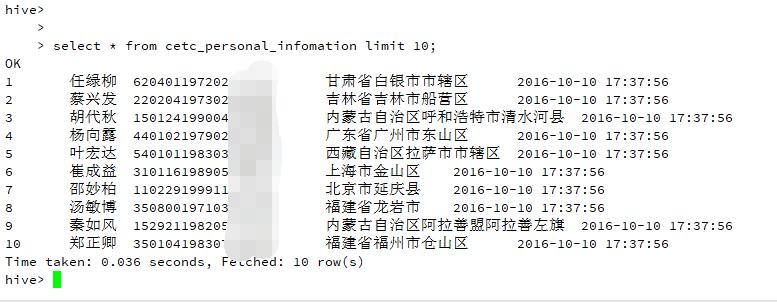
可以看到这次是正常的。
hive 建表的时候一定要注意指定分隔符,分割符号根据源数据的情况具体看。